Stein's method
Stein's method is a general method in probability theory to obtain bounds on the distance between two probability distributions with respect to a probability metric. It was introduced by Charles Stein, who first published it 1972,[1] to obtain a bound between the distribution of a sum of 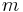 -dependent sequence of random variables and a standard normal distribution in the Kolmogorov (uniform) metric and hence to prove not only a central limit theorem, but also bounds on the rates of convergence for the given metric.
-dependent sequence of random variables and a standard normal distribution in the Kolmogorov (uniform) metric and hence to prove not only a central limit theorem, but also bounds on the rates of convergence for the given metric.
Contents |
History
At the end of the 1960s, unsatisfied with the by-then known proofs of a specific central limit theorem, Charles Stein developed a new way of proving the theorem for his statistics lecture.[2] The seminal paper[1] was presented in 1970 at the sixth Berkeley Symposium and published in the corresponding proceedings.
Later, his Ph.D. student Louis Chen Hsiao Yun modified the method so as to obtain approximation results for the Poisson distribution,[3] therefore the method is often referred to as Stein-Chen method. Whereas moderate attention was given to the new method in the 70s, it has undergone major development in the 80s, where many important contributions were made and on which today's view of the method are largely based. Probably the most important contributions are the monograph by Stein (1986), where he presents his view of the method and the concept of auxiliary randomisation, in particular using exchangeable pairs, and the articles by Barbour (1988) and Götze (1991), who introduced the so-called generator interpretation, which made it possible to easily adapt the method to many other probability distributions. An important contribution was also an article by Bolthausen (1984) on a long-standing open problem around the so-called combinatorial central limit theorem, which surely helped the method to become widely known.
In the 1990s the method was adapted to a variety of distributions, such as Gaussian processes by Barbour (1990), the binomial distribution by Ehm (1991), Poisson processes by Barbour and Brown (1992), the Gamma distribution by Luk (1994), and many others.
The basic approach
Probability metrics
Stein's method is a way to bound the distance of two probability distributions in a specific probability metric. To be tractable with the method, the metric must be given in the form
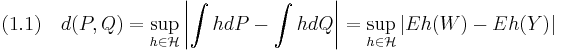
Here, 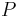 and
and 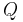 are probability measures on a measurable space
are probability measures on a measurable space 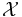 ,
, 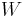 and
and 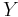 are random variables with distribution and respectively,
are random variables with distribution and respectively, 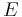 is the usual expectation operator and
is the usual expectation operator and 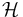 is a set of functions from to the real numbers. This set has to be large enough, so that the above definition indeed yields a metric. Important examples are the total variation metric, where we let consist of all the indicator functions of measurable sets, the Kolmogorov (uniform) metric for probability measures on the real numbers, where we consider all the half-line indicator functions, and the Lipschitz (first order Wasserstein; Kantorovich) metric, where the underlying space is itself a metric space and we take the set to be all Lipschitz-continuous functions with Lipschitz-constant 1. However, note that not every metric can be represented in the form (1.1).
is a set of functions from to the real numbers. This set has to be large enough, so that the above definition indeed yields a metric. Important examples are the total variation metric, where we let consist of all the indicator functions of measurable sets, the Kolmogorov (uniform) metric for probability measures on the real numbers, where we consider all the half-line indicator functions, and the Lipschitz (first order Wasserstein; Kantorovich) metric, where the underlying space is itself a metric space and we take the set to be all Lipschitz-continuous functions with Lipschitz-constant 1. However, note that not every metric can be represented in the form (1.1).
In what follows we think of as a complicated distribution (e.g. a sum of dependent random variables), which we want to approximate by a much simpler and tractable distribution (e.g. the standard normal distribution to obtain a central limit theorem).
The Stein operator
We assume now that the distribution is a fixed distribution; in what follows we shall in particular consider the case where is the standard normal distribution, which serves as a classical example of the application of Stein's method.
First of all, we need an operator 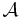 which acts on functions
which acts on functions 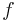 from to the real numbers, and which 'characterizes' the distribution in the sense that the following equivalence holds:
from to the real numbers, and which 'characterizes' the distribution in the sense that the following equivalence holds:

We call such an operator the Stein operator. For the standard normal distribution, Stein's lemma exactly yields such an operator:

thus we can take
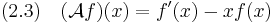
We note that there are in general infinitely many such operators and it still remains an open question, which one to choose. However, it seems that for many distributions there is a particular good one, like (2.3) for the normal distribution.
There are different ways to find Stein operators. But by far the most important one is via generators. This approach was, as already mentioned, introduced by Barbour and Götze. Assume that 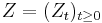 is a (homogeneous) continuous time Markov process taking values in . If
is a (homogeneous) continuous time Markov process taking values in . If 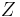 has the stationary distribution it is easy to see that, if is the generator of , we have
has the stationary distribution it is easy to see that, if is the generator of , we have 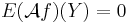 for a large set of functions . Thus, generators are natural candidates for Stein operators and this approach will also help us for later computations.
for a large set of functions . Thus, generators are natural candidates for Stein operators and this approach will also help us for later computations.
Setting up the Stein equation
Observe now that saying that is close to with respect to 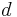 is equivalent to saying that the difference of expectations in (1.1) is close to 0, and indeed if
is equivalent to saying that the difference of expectations in (1.1) is close to 0, and indeed if 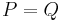 it is equal to 0. We hope now that the operator exhibits the same behavior: clearly if we have
it is equal to 0. We hope now that the operator exhibits the same behavior: clearly if we have 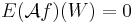 and hopefully if
and hopefully if 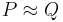 we have
we have 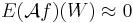 .
.
To make this statement rigorous we could find a function , such that, for a given function 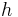 ,
,

so that the behavior of the right hand side is reproduced by the operator and . However, this equation is too general. We solve instead the more specific equation
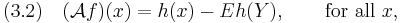
which is called Stein equation. Replacing  by and taking expectation with respect to , we are back to (3.1), which is what we effectively want. Now all the effort is worth only if the left hand side of (3.1) is easier to bound than the right hand side. This is, surprisingly, often the case.
by and taking expectation with respect to , we are back to (3.1), which is what we effectively want. Now all the effort is worth only if the left hand side of (3.1) is easier to bound than the right hand side. This is, surprisingly, often the case.
If is the standard normal distribution and we use (2.3), the corresponding Stein equation is
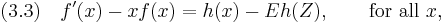
which is just an ordinary differential equation.
Solving the Stein equation
Now, in general, we cannot say much about how the equation (3.2) is to be solved. However, there are important cases, where we can.
Analytic methods. We see from (3.3) that equation (3.2) can in particular be a differential equation (if is concentrated on the integers, it will often turn out to be a difference equation). As there are many methods available to treat such equations, we can use them to solve the equation. For example, (3.3) can be easily solved explicitly:
![(4.1)\quad
f(x) = e^{x^2/2}\int_{-\infty}^x [h(s)-E h(Y)]e^{-s^2/2}ds.](/2012-wikipedia_en_all_nopic_01_2012/I/0ee5664941d4d033fef8b283a540f7f7.png)
Generator method. If is the generator of a Markov process 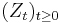 as explained before, we can give a general solution to (3.2):
as explained before, we can give a general solution to (3.2):
![(4.2)\quad
f(x) = -\int_0^\infty [E^x h(Z_t)-E h(Y)] dt.](/2012-wikipedia_en_all_nopic_01_2012/I/49b608c90206d9bae7b24b06525f44f4.png)
where 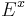 denotes expectation with respect to the process being started in . However, one still has to prove that the solution (4.2) exists for all desired functions
denotes expectation with respect to the process being started in . However, one still has to prove that the solution (4.2) exists for all desired functions 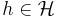 .
.
Properties of the solution to the Stein equation
After showing the existence of a solution to (3.2) we can now try to analyze its properties. Usually, one tries to give bounds on and its derivatives (which has to be carefully defined if is a more complicated space) or differences in terms of and its derivatives or differences, that is, inequalities of the form
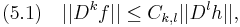
for some specific 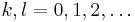 (typically
(typically 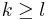 or
or 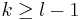 , respectively, depending on the form of the Stein operator) and where often
, respectively, depending on the form of the Stein operator) and where often  is taken to be the supremum norm. Here,
is taken to be the supremum norm. Here, 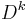 denotes the differential operator, but in discrete settings it usually refers to a difference operator. The constants
denotes the differential operator, but in discrete settings it usually refers to a difference operator. The constants 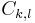 may contain the parameters of the distribution . If there are any, they are often referred to as Stein factors or magic factors.
may contain the parameters of the distribution . If there are any, they are often referred to as Stein factors or magic factors.
In the case of (4.1) we can prove for the supremum norm that
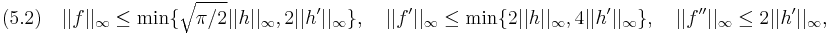
where the last bound is of course only applicable if is differentiable (or at least Lipschitz-continuous, which, for example, is not the case if we regard the total variation metric or the Kolmogorov metric!). As the standard normal distribution has no extra parameters, in this specific case, the constants are free of additional parameters.
Note that, up to this point, we did not make use of the random variable . So, the steps up to here in general have to be calculated only once for a specific combination of distribution , metric and Stein operator . However, if we have bounds in the general form (5.1), we usually are able to treat many probability metrics together. Furthermore as there is often a particular 'good' Stein operator for a distribution (e.g., no other operator than (2.3) has been used for the standard normal distribution up to now), one can often just start with the next step below, if bounds of the form (5.1) are already available (which is the case for many distributions).
An abstract approximation theorem
We are now in a position to bound the left hand side of (3.1). As this step heavily depends on the form of the Stein operator, we directly regard the case of the standard normal distribution.
Now, at this point we could directly plug in our random variable which we want to approximate and try to find upper bounds. However, it is often fruitful to formulate a more general theorem using only abstract properties of . Let us consider here the case of local dependence.
To this end, assume that 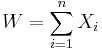 is a sum of random variables such that the
is a sum of random variables such that the 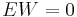 and variance
and variance 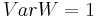 . Assume that, for every
. Assume that, for every 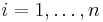 , there is a set
, there is a set 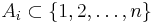 , such that
, such that 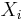 is independent of all the random variables
is independent of all the random variables 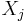 with
with 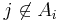 . We call this set the 'neighborhood' of . Likewise let
. We call this set the 'neighborhood' of . Likewise let 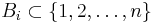 be a set such that all with
be a set such that all with 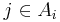 are independent of all
are independent of all 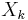 ,
, 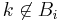 . We can think of
. We can think of 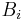 as the neighbors in the neighborhood of , a second-order neighborhood, so to speak. For a set
as the neighbors in the neighborhood of , a second-order neighborhood, so to speak. For a set 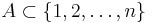 define now the sum
define now the sum 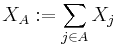 .
.
Using basically only Taylor expansion, it is possible to prove that
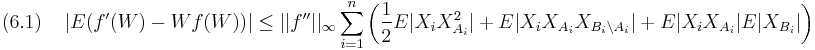
Note that, if we follow this line of argument, we can bound (1.1) only for functions where  is bounded because of the third inequality of (5.2) (and in fact, if has discontinuities, so will
is bounded because of the third inequality of (5.2) (and in fact, if has discontinuities, so will  ). To obtain a bound similar to (6.1) which contains only the expressions
). To obtain a bound similar to (6.1) which contains only the expressions  and
and 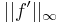 , the argument is much more involved and the result is not as simple as (6.1); however, it can be done.
, the argument is much more involved and the result is not as simple as (6.1); however, it can be done.
Theorem A. If is as described above, we have for the Lipschitz metric 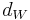 that
that
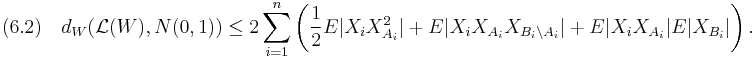
Proof. Recall that the Lipschitz metric is of the form (1.1) where the functions are Lipschitz-continuous with Lipschitz-constant 1, thus 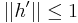 . Combining this with (6.1) and the last bound in (5.2) proves the theorem.
. Combining this with (6.1) and the last bound in (5.2) proves the theorem.
Thus, roughly speaking, we have proved that, to calculate the Lipschitz-distance between a with local dependence structure and a standard normal distribution, we only need to know the third moments of and the size of the neighborhoods 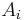 and .
and .
Application of the theorem
We can treat the case of sums of independent and identically distributed random variables with Theorem A. So assume now that 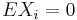 ,
, 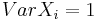 and
and 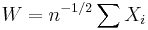 . We can take
. We can take 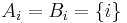 and we obtain from Theorem A that
and we obtain from Theorem A that
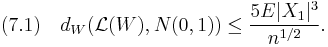
Connections to other methods
- Lindeberg's method. Lindeberg (1922) introduced in a seminal article a method, where the difference in (1.1) is directly bounded. This method usually also heavily relies on Taylor expansion and thus shows some similarities with Stein's method.
- Tikhomirov's method. Clearly the approach via (1.1) and (3.1) does not involve characteristic functions. However, Tikhomirov (1980) presented a proof of a central limit theorem based on characteristic functions and a differential operator similar to (2.3). The basic observation is that the characteristic function
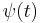 of the standard normal distribution satisfies the differential equation
of the standard normal distribution satisfies the differential equation 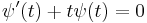 for all
for all 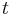 . Thus, if the characteristic function
. Thus, if the characteristic function 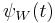 of is such that
of is such that 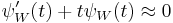 we expect that
we expect that 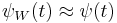 and hence that is close to the normal distribution. Tikhomirov states in his paper that he was inspired by Stein's seminal paper.
and hence that is close to the normal distribution. Tikhomirov states in his paper that he was inspired by Stein's seminal paper.
Literature
The following text is advanced, and gives a comprehensive overview of the normal case
- Chen, L.H.Y., Goldstein, L., and Shao, Q.M (2011). Normal approximation by Stein's method. www.springer.com. ISBN 978-3-642-15006-7.
Another advanced book, but having some introductory character, is
- ed. Barbour, A.D. and Chen, L.H.Y. (2005). An introduction to Stein's method. Lecture Notes Series, Institute for Mathematical Sciences, National University of Singapore. 4. Singapore University Press. ISBN 981256280X.
A standard reference is the book by Stein,
- Stein, C. (1986). Approximate computation of expectations. Institute of Mathematical Statistics Lecture Notes, Monograph Series, 7. Hayward, Calif.: Institute of Mathematical Statistics. ISBN 0940600080.
which contains a lot of interesting material, but may be a little hard to understand at first reading.
Despite its age, there are few standard introductory books about Stein's method available. The following recent textbook has a chapter (Chapter 2) devoted to introducing Stein's method:
- Ross, Sheldon and Peköz, Erol (2007). A second course in probability. www.ProbabilityBookstore.com. ISBN 978-0979570407.
Although the book
- Barbour, A. D. and Holst, L. and Janson, S. (1992). Poisson approximation. Oxford Studies in Probability. 2. The Clarendon Press Oxford University Press. ISBN 0198522355.
is by large parts about Poisson approximation, it contains nevertheless a lot of information about the generator approach, in particular in the context of Poisson process approximation.
References
- ^ a b Stein, C. (1972). "A bound for the error in the normal approximation to the distribution of a sum of dependent random variables". Proceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability: 583–602. MR402873. Zbl 0278.60026. http://projecteuclid.org/euclid.bsmsp/1200514239.
- ^ Charles Stein: The Invariant, the Direct and the "Pretentious". Interview given in 2003 in Singapore
- ^ Chen, L.H.Y. (1975). "Poisson approximation for dependent trials". Annals of Probability 3 (3): 534–545. doi:10.1214/aop/1176996359. JSTOR 2959474. MR428387. Zbl 0335.60016.
Bibliography
- Barbour, A. D. (1988). "Stein's method and Poisson process convergence". J. Appl. Probab. (Applied Probability Trust) 25A: 175–184. doi:10.2307/3214155. JSTOR 3214155.
- Barbour, A. D. (1990). "Stein's method for diffusion approximations". Probab. Theory Related Fields 84 (3): 297–322. doi:10.1007/BF01197887.
- Barbour, A. D. and Brown, T. C. (1992). "Stein's method and point process approximation". Stochastic Process. Appl. 43 (1): 9–31. doi:10.1016/0304-4149(92)90073-Y.
- Bolthausen, E. (1984). "An estimate of the remainder in a combinatorial central limit theorem". Z. Wahrsch. Verw. Gebiete 66 (3): 379–386. doi:10.1007/BF00533704.
- Ehm, W. (1991). "Binomial approximation to the Poisson binomial distribution". Statist. Probab. Lett. 11 (1): 7–16. doi:10.1016/0167-7152(91)90170-V.
- Götze, F. (1991). "On the rate of convergence in the multivariate CLT". Ann. Probab. 19 (2): 724–739. doi:10.1214/aop/1176990448.
- Lindeberg, J. W. (1922). "Eine neue Herleitung des Exponentialgesetzes in der Wahrscheinlichkeitsrechung". Math. Z. 15 (1): 211–225. doi:10.1007/BF01494395.
- Luk, H. M. (1994). Stein's method for the gamma distribution and related statistical applications. Dissertation.
- Stein, C. (1986). Approximate computation of expectations. Institute of Mathematical Statistics Lecture Notes, Monograph Series, 7. ISBN 0940600080.
- Tikhomirov, A. N. (1980). "Convergence rate in the central limit theorem for weakly dependent random variables". Teor. Veroyatnost. I Primenen. 25: 800–818. English translation in Theory Probab. Appl. 25 (1980–81): 790–809.